안녕하세요 틴구입니다
오늘은 Hashtable이라는 것에 대해서 적어보려고 합니다.
1.Hashtable
Hash Table: 키에 대한 데이터를 저장하는 데이터 구조이고
키만 알면 데이터가 어디에 저장되어있는지 알 수 있는 데이터 구조입니다.
장점 : 데이터 저장/읽기 속도가 빠릅니다.
(검색에서 배열보다 해쉬 테이블 구조가 더 빠르다)
검색에서 배열보다 해쉬테이블 구조가 좋은 이유
배열 : index별로 일일이 검색해야, index를 순차적으로 검색할 때 찾고자 하는 데이터가
배열의 마지막 인덱스에 값인 경우 시간이 오래 걸립니다.
해쉬 테이블 : 데이터를 받고 그에 해당하는 키를 찾으면 해쉬 함수를 한 번만 돌리면
바로 그 데이터 저장 위치를 해쉬 테이블에서 찾을 수 있습니다.
키에 대한 해쉬 값이 있는지 없는지 중복체크가 쉬움
배열 같은 경우는 index에 대한 값이 있는지 없는지
중복 체크할 때 기존 데이터를 일일이 봐야 함
단점 : 일반적으로 저장공간이 많이 필요 여러 key에 해당하는 해쉬 주소가 동일한 경우
충돌이 발생 따라서 충돌을 해결하기 위한 별도의 자료구조가 필요
2. 코드 구성 및 분석

Hash.h를 클래스 - 인라인으로 생성한 헤더 파일이다.
기본 구성은 위 코드의 구성처럼 짜여 있다
여기서 템플릿을 통해 인자 타입에 따라 별도의 처리 함수를 만들어놓고 작업할 수 있게 해주자
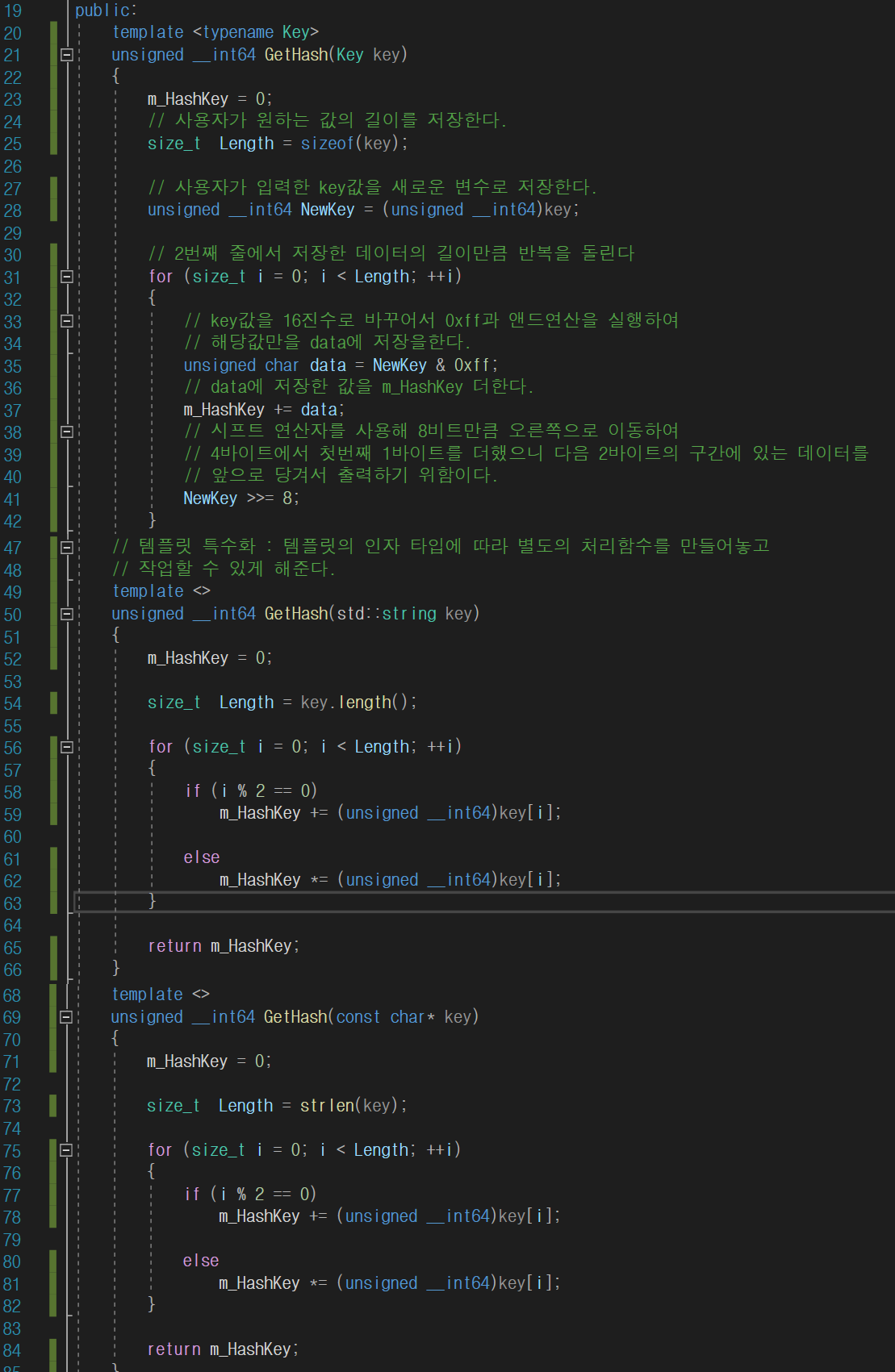
인자로 들어오는 타입에 따라 구성을 다르게 해 놓았다
첫 번째 GetHash의 경우는 주석으로 각각의 코드 분석을 해놨기 때문에 넘어가겠습니다.
2번째 3번째의 GetHash의 경우는 문자열을 출력하기 위한 코드 구성입니다.
둘 다 공통적으로 문자열로 들어온 문자열의 크기를 구해준 뒤
for문에서 문자열의 크기만큼 반복문을 돌린다
그 안에서 짝수일 때는 아스키코드값만큼을 m_HashKey에다가 더해주고
홀수일 때는 곱해주어 최대한 HashKey코드가 다양하게 나오도록 해준다.
ex)

위의 사진처럼 Output함수를 만들어 key값의 길이와 m_HashKey의 값을 확인해봅시다

insert함수는 뒤에서 설명드리겠습니다.
위의 사진처럼 코드를 구성하고 출력을 하게 되면
3
짝수 : 97
홀수 : 9506
짝수 : 9605 가 출력이 됩니다.
맨 위의 3은 abc의 문자열 길이를 뜻하고
abc의 아스키코드값을 확인해보면 97 98 99 인 것을 알 수 있는데
위의 내용을 코드에 넣어보면
for문을 Length인 0 < 3 만큼 반복한다는 것이고
0은 짝수이기 때문에 아스키코드값인 97을 HashKey값에 더하고
그다음은 ++되어 1이 되는데 1은 홀수기 때문에 97 x 98을 하여 9506
그다음은 짝수기 때문에 9506 + 99를 하여 9605가 출력되는 것입니다.
결국 'abc'문자열의 m_HashKey는 9605가 되는 것입니다.

class CHashNode

class CHashTableIterator

class CHashTable
참고 위 3개의 사진은 한 헤더파일의 클래스 - 인라인 형식이며 한 헤더파일을 3분할 해서 올린 사진입니다
리스트의 경우는 너무 길어서 코드는 생략하도록 하겠습니다(전에 올린 리스트 코드 참고)
HashTable.h의 코드는 함수마다 주석으로 설명을 적어두었으니 주석 참고하시면 될 거 같습니다!!
중요한점 : HashTable의 크기인 HASHSIZE를 소수로 잡아준다. 설명은 class HashTable위의 주석 참고.
종속적 형식인 이름을 쓸 때에는 typename 접두사를 붙혀줘야한다. (Get함수 참고 54번줄)
'c++ > 자료구조' 카테고리의 다른 글
| 20210810 Dijkstra(다익스트라) 알고리즘 (0) | 2021.08.11 |
|---|---|
| 20210810 Graph알고리즘 (0) | 2021.08.11 |
| 20210810 병합정렬(합병정렬) (0) | 2021.08.10 |
| 20210806 Heap정렬, Quick정렬 (0) | 2021.08.08 |
| 20210805 자가균형 이진트리 AVLTree (0) | 2021.08.06 |

댓글