안녕하세요 틴구입니다.
오늘은 Heap정렬이랑 Quick정렬에 대해서 설명드리겠습니다!
Heap정렬
우선 Heap정렬은 이진트리를 베이스로하는 정렬 알고리즘입니다.
그래서 트리에 대한 구조를 이해할 수 있어야하고 이진트리를 이해할 수 있어야 합니다.
Heap정렬에는 최대힙과 최소힙으로 나뉘는데
최대힙이란
모든 자료에서 부모노드의 값이 자식노드보다 큰 구조를 의미합니다.
여기서 중요한건 반드시 완전이진트리 구조가 전제가 되어야 합니다.
최대힙은 내림차순 정렬이 됩니다.

최소힙은
부모노드의 값이 자식노드보다 작은 경우를 의미하고
최소힙은 오름차순 정렬이 됩니다.

코드구성
그럼 힙정렬을 구성하는 코드를 만들어 볼게요.
우선 헤더파일에 추가 - 클래스 - 인라인으로
Heap.h를 만들어줍니다.

static bool sortFunction함수를 만들어 리턴값에 따라 최대힙과 최소힙을 구분지어줍니다.

push함수를 만들어주어 배열의 사이즈가 꽉차면 추가로 자동으로 늘려주고
InsertHeap함수로 늘린만큼의 데이터값을 추가하는 구성입니다.

해당 값들을 반환해주는 함수와 트리의 top을 구해주는 함수와 clear함수를 만들어줍니다.
int Size()함수의 경우 m_Size를 리턴해주어 필요한 곳에서 사용할 수 있게 만들어줍니다.
bool empty()는 리턴값으로 m_Size == 0;을 해주어 비어있는지 확인해주는 함수입니다.
T top()함수는 0번째 인덱스 값을 리턴해주어 처음의 데이터 값을 알아내는 함수입니다.

위의 InsertHeap은
Push()함수 내부에서 사용되는 함수인데
Index값의 부모인덱스를 구해준뒤 부모인덱스 값이 Index보다 클 경우
두 값을 서로 바꿔주어 정렬을 해주는 함수입니다.
현재 m_Func가 좌측 인자가 우측인자보다 클 경우 참으로 코드 구성을 해놨기 때문에
최소힙 정렬이 진행중입니다.

pop함수는 데이터 값을 출력하기 위한 함수인데
마지막에 추가된 노드를 루트로 올리고 그 노드를 DeleteHeap함수의 인자로 넣어
DeleteHeap을 진행하는 코드 구성입니다.
DeleteHeap함수는 아래에서 설명드리겠습니다.

마지막으로 DeleteHeap함수입니다
DeleteHeap함수같은 경우는 pop()함수의 내부에서 사용하는 함수인데
인자로 들어온 Index의 왼쪽자식과 오른쪽 자식의 값을 비교하여 더 작은것을 위로 올려주며
재귀 방식으로 마지막 자식노드까지 작은 노드를 부모노드랑 바꿔주면서 정렬시켜주는 함수를 진행하는 방식입니다.
자식노드 구하는 방법
여기서 왼쪽자식노드를 구하는 방법은 Index * 2 + 1이고
오른쪽 자식노드는 Index * 2 + 2로 즉 왼쪽자식노드 + 1이 됩니다.
main.cpp
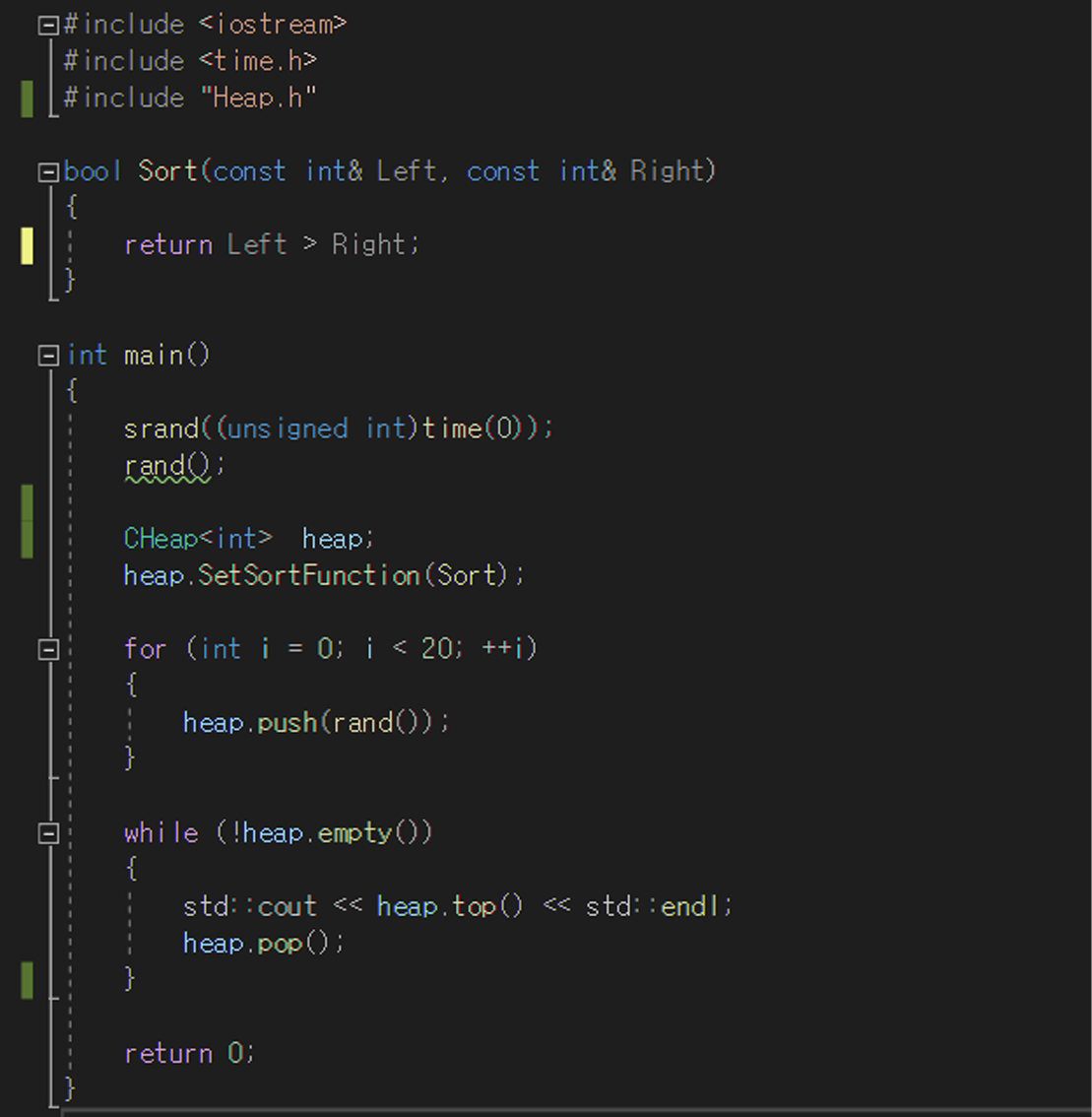
main.cpp를 이런식으로 코드를 구성하고 출력을 하게되면

위의 숫자처럼 오름차순 정렬되어서 출력이 됩니다.
main.cpp안에 Sort함수에서 Left < Right;로 리턴값을 바꿔주면 최대힙으로 바뀌어 내림차순 정렬로 바뀌게 됩니다.
Quick정렬
퀵정렬이란 피봇을 기준으로 작은 것을 왼쪽 큰것은 오른쪽으로 정렬하며 정렬된 배열을 재귀적으로 정렬하는 정렬 알고리즘이라고 합니다.
우선 Heap정렬과 동일하게
헤더파일에 인라인으로 class CQuick파일을 생성해줍니다.
기본 틀은 Heap정렬과 동일합니다.
기본 class 틀은 생략하겠습니다 완전 동일.(카테고리 코드구성)
코드구성
Push()
Quick정렬의 push 함수의 경우 두가지를 만들수가 있습니다
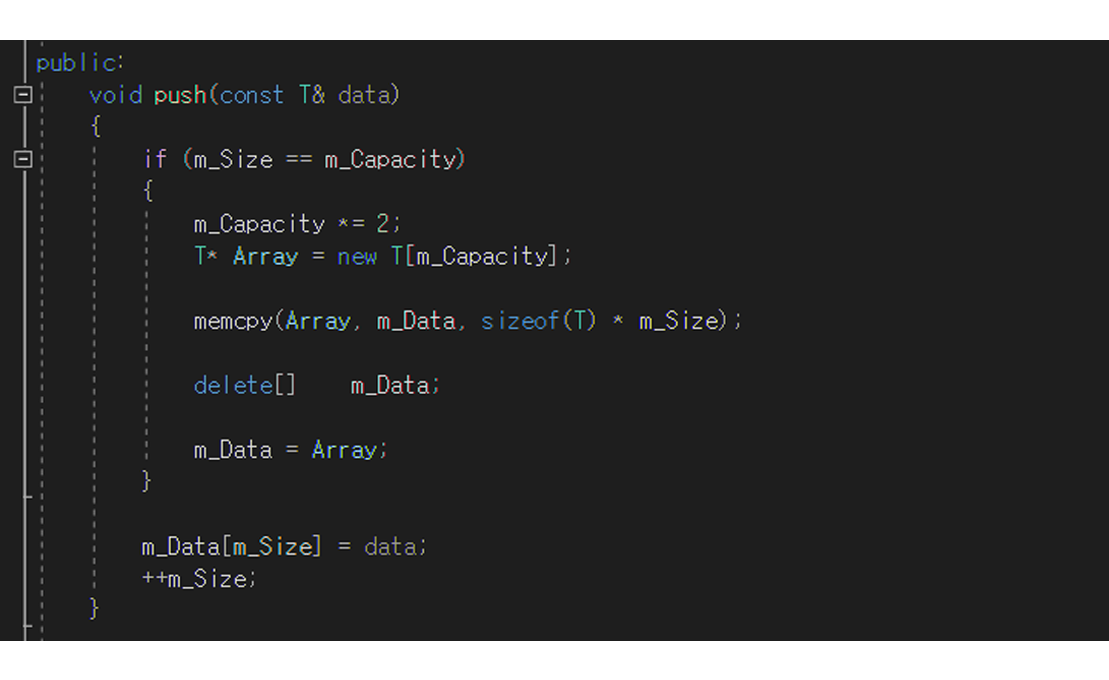
Heap정렬에서와 동일한 push함수
단. 중간에 InsertHeap함수가 빠지게된다.

위의 함수는 배열을 통채로 집어넣어 적용시키는 push함수이다.

Quick정렬 같은 경우는 재귀적으로 처리를 하게됩니다.
우선 위의 코드를 보기전에 아래의 Partition함수를 봅시다.
Partition함수는 pivot값을 구하기 위한 함수입니다.

Partition함수 설명
만약에 숫자 구성의 인덱스가
0, 1, 2, 3, 4, 5, 6, 7, 8, 9 까지 구성되어있고
5, 2, 4, 7, 9, 3, 1, 6, 8 로 구성이 되어있다면
기준값을 첫 인덱스인 5로 정하고
Low의 값은 첫인덱스인 5
(do while문에 의해 ++을 해줄거기 때문에 이렇게 설정)
High은 마지막 인덱스값인 9 - 1 로 Right를 구성되어 인자로 들어왔기 때문에 +1을 해주면 9가 됩니다.
(+1을 해준 이유는 do while에서 --를 해줄거기 때문)
처음 do whil 문에 들어오게 되고 Low < High의 조건에서 true가 되어 코드블록안의 do while문으로 들어가게 되고
do while문의 형태에 따라서 조건식에 영향을 받지 않고 ++Low를 합니다.
++Low를 하면 1번인덱스가 되고 값이 2가 됩니다.
여기서 조건식을 체크해보면 Low인덱스는 Right인덱스보다 작거나 같고 (true) Value의 값인 5가 Low의 값인 2보다 크기 때문에 trur가 되어 다시 do while문으로 들어가 ++Low를 하게됩니다.
계속 돌다보면 Low의 인덱스가 3 값이 7시점에서 Value의 값인 5보다 크기때문에 do while문을 빠져나오게 되고
그 밑의 do while문으로 들어가게 됩니다.
여기서도 do while문의 형식에 의해 조건식 상관없이 --High를 해주면 High의 인덱스는 8이 되고 값은 8이 됩니다.
조건식을 보면 High인덱스는 Left인덱스보다 크거나 작고(true) High값인 8이 Value값인 5보다 커서 조건식이 true가 되어 다시 do while문을 들어가게 됩니다. 계속 반복하다보면
High의 인덱스가 6, 값이 1인 시점에서 조건식 false가 되어 do while문을 빠져나오게 되고 그 아래에 있는 if문으로 들어가 Low인덱스가 High인덱스보다 작기때문에
그 두개의 값들을 바꿔주어 5, 2, 4, 1, 9, 3, 6, 7, 8 이 되었는데 아직도 Low가 High보다 작기떄문에 다시 do while문을 들어가고
++Low가 되어 Low의 인덱스는 4 값은 9가 되고 조건식 false로 do while문을 빠져나오고 밑에 do while문에 들어가 --High를 하면 인덱스 5 값은 3이되는데 여기서 조건식이 flase가 되어 do while문을 빠져나가고 if문에 들어가
Low가 High보다 작기때문에 Low의 값과 High의 값을 바꿔주어
5, 2, 4, 1, 3, 9, 6, 7, 8 이 됩니다
다시 do while문에 들어가 ++Low 인덱스는 5 값은 9 조건식 false 빠져나오고 do while문 들어가서 --High 인덱스 4 값은 3이 되어 완전한 do while문을 빠져나가 Array[Left]값을 Array[High]값으로 바꾸어 주면
3, 2, 4, 1, 5, 9, 6, 7, 8이 되어 Pivot은 5가 되는겁니다
으따 길다
쨋든 이런식으로 Pivot을 구해서 Left 부터 Pivot -1 까지의 데이터값과
Pivot + 1 부터 Right의 데이터 값을 분할해서 계속 들어가면서 정렬을 해주게 되는것입니다.
'c++ > 자료구조' 카테고리의 다른 글
| 20210810 Graph알고리즘 (0) | 2021.08.11 |
|---|---|
| 20210810 병합정렬(합병정렬) (0) | 2021.08.10 |
| 20210805 자가균형 이진트리 AVLTree (0) | 2021.08.06 |
| 20210804 이진 트리 순회, erase (0) | 2021.08.05 |
| 20210803 이진 트리 (재귀 함수 활용) (0) | 2021.08.04 |

댓글